BigData-- 大数据常用开源组件一览
概述
最近有一个项目是跟公司的大数据平台有关,这里梳理一下常用的大数据组件,做个记录,同时,还有一个原因,就是希望用比较简洁的语言让我女朋友能对大数据的整体架构有个大致了解。 大数据平台的架构不一而足,市面上的开源工具非常多,所选用的组件也是因人而异,不过都是为了具体业务应用场景而服务,这里选取一些常用的开源组件,试图从大数据处理的整个流程出发,将各个开源组件的功能特点,适用场景等讲清楚,个人观点,难免纰漏。
大数据处理流程
在介绍大数据组件之前,先把大数据的整体处理流程梳理一下,因为要想了解整个大数据组件体系,首先得清楚我们要面临的问题,了解了问题才能去找相应的解决方案,如果只是一猛子扎进hadoop 体系里,反而会越看越迷糊。 大数据的处理流程大致包括数据收集,数据存储,数据计算与数据分析这四个阶段,其实数据计算与分析算是一个阶段,这里为了以后区分组件的方便将其分开,数据计算可以理解为计算引擎那部分,数据分析就是更上层的BI分析工具等等。接下来就从这四个流程出发,简单介绍下常用工具。
数据收集
在大数据还未兴盛之前,我们一般是将数据存储到关系型数据库(Mysql等),或者文本文件(日志文件等)中,这种方法在数据量不大的情况下是可以的,但在数据量达到TB,甚至PB级别,这种情况就不适用了。为了能够存储这种量级的数据,大数据存储组件应运而生,这里先暂时不说大数据存储,先说数据收集。出现了大数据存储组件之后,有一个问题就是要将数据收集到大数据存储组件中,于是,相应的组件也就出现了:
以下是收集组件:
- Sqoop:Sqoop是一个工具,用来在关系型数据库和Hadoop之间传输数据。你可以使用Sqoop来从RDBMS(MySQL or Oracle)导入数据到Hadoop环境里,或者通过MapReduce转换数据,把数据导回到RDBMS。
- Flume: Flume 是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume支持对数据进行简单处理,并写入各种数据接受方(可定制)。
- Logstash:也是一个应用程序日志、事件的传输、处理、管理和搜索的平台。可以用它来统一对应用程序日志进行收集管理,提供了Web接口用于查询和统计。
除了收集之外,因为巨大的IO压力,我们通常会在收集组件与数据存储组件之间加一层消息队列用于削峰填谷,降低IO压力,常用的组件包括:
- Kafka 是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模网站中的所有动作流数据,目前已成为大数据系统在异步和分布式消息之间的最佳选择。
- RabbitMQ 是一个受欢迎的消息代理系统,通常用于应用程序之间或者程序的不同组件之间通过消息来进行集成。RabbitMQ提供可靠的应用消息发送、易于使用、支持所有主流操作系统、支持大量开发者平台。
- ActiveMQ 是Apache出品,号称“最流行的,最强大”的开源消息集成模式服务器。ActiveMQ特点是速度快,支持多种跨语言的客户端和协议,其企业集成模式和许多先进的功能易于使用,是一个完全支持JMS1.1和J2EE 1.4规范的JMS Provider实现。
MQ组件的对比可以参考阿里中间件团队做的压测RocketMQ与kafka对比(18项差异),Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能
数据存储
数据存储这块分为两个部分,一部分是底层的文件系统,还有一部分就是之上的数据库或数据仓库。
文件系统
大数据文件系统其实是大数据平台架构最为基础的组件,其他的组件或多或少都会依赖这个基础组件,
目前应用最为广泛的大数据存储文件系统非Hadoop 的HDFS莫属,除此之外,简单介绍下号称可以取代HDFS的Ceph。
- HDFS:HDFS是一个高度容错性(多副本,自恢复)的分布式文件系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的访问,不支持低延迟数据访问,不支持多用户写入、任意修改文件。HDFS是Hadoop 大数据工具栈里最基础有也是最重要的一个组件,基于Google的GFS开发。
- Ceph:Ceph是一个符合POSIX、开源的分布式存储系统。最早是加州大学圣克鲁兹分校(USSC)博士生 Sage Weil 博士期间的一项有关存储系统的研究项目,Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。真正让ceph叱咤风云的是开源云计算解决方案Openstack,Openstack+Ceph的方案已被业界广泛使用。
数据库或数据仓库
针对大数据的数据库大部分是NOSQL数据库,这里顺便澄清一下,NOSQL的真正意义是“ not only sql”,并非NOSQL是RMDB的对立面。
- Hbase:是一个开源的面向列的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable规模的服务。因此,它可以容错地存储海量稀疏的数据。
- MongoDB:一个基于分布式文件存储的数据库,面向文件,旨在为web应用提供可扩展的高性能数据存储解决方案。介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富、最像关系数据库的产品。
- Cassandra:是一个混合型的非关系的数据库,类似于Google的BigTable,由Facebook开发。
- Neo4j:一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。
数据计算
简单介绍以下目前比较流行的几种大数据计算框架:
- MapReduce:最为知名的当属MapReduce,MapReduce属于一种批处理计算框架,借助于HDFS,基于磁盘进行数据计算,MapReduce的容错能力超强,适合处理巨大规模集群(几百上千个节点)下长时间非实时的大计算任务;但其实时性较差。Hadoop系列的Hive,Pig等数据仓库都是基于MapReduce做的。
- Spark:是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量的廉价硬件之上,形成集群。Spark是MapReduce的替代方案,而且兼容HDFS等分布式存储层,可融入Hadoop的生态系统,以弥补缺失MapReduce的不足。适合迭代计算(常见于machine learning领域,比如PageRank)和交互式计算(data mining领域,比如SQL查询)。
- Storm:典型的流计算系统,会对随时进入系统的数据进行计算,近实时处理需求的任务很适合使用流处理模式,适于处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据,类似框架还有 spark streaming。
除了计算框架外,因为是分布式系统,我们还需要对计算资源进行分配调度,以及各种服务间的协调,发现,配置管理等,所以这里又出现了两个重要的组件:
- Yarn:Hadoop 2.0中推出的非常重要的资源管理框架,负责集群资源管理和调度,MapReduce就是运行在YARN上的离线处理框架。
- Zookeeper:是Google的Chubby一个开源的实现,是Apache软件基金会的一个软件项目,他为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
两者的区别是:Yarn是resource management,解决的问题是怎样提高整个集群的资源利用率。Zookeeper是 Coordination,解决的是集群中各种服务的发现,同步,协调配合以保持整个集群的稳定。
数据分析
数据分析的工具就更多了,这里列举一些业界用的比较多的,相对成熟的工具:
- Hive,Pig:两者都是Hadoop开源的分析工具,将这两个工具放在一起的原因是,他们底层都是基于MapReduce实现的,不过Hive是采用SQL的形式调用,而Pig是用脚本的形式,因为SQL的便利易用,Hive已逐渐取代Pig。
- Impala: Impala是Cloudera开发的一款用来进行大数据实时查询分析的开源工具,它能够实现通过SQL风格来操作数据,Impala没有再使用缓慢的 Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
- Presto:随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求,Facebook开发人员便开发了Presto,Presto依赖于Hive meta,摒弃了MapReduce方法,通过使用分布式查询,可以快速高效的完成海量数据的查询。
- Spark:这里又提了Spark是因为Spark的应用越来越广泛,而且Spark 集成了很多机器学习的框架,可以很方便的调用。
- Kylin:Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
整体框架
以上是按照数据处理的流程来区分的,这里从网上找到一张由下而上的整体架构:
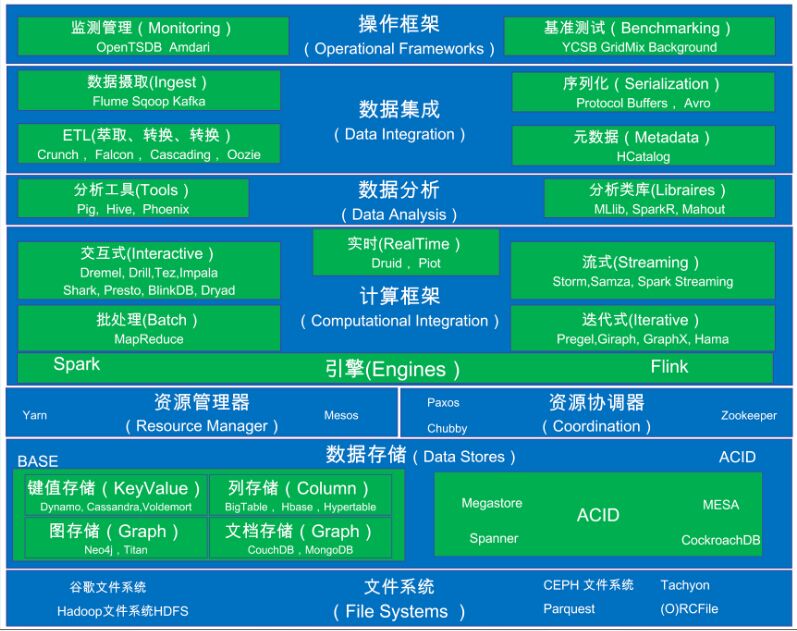
参考文章
Big data architecture - Introduction
Exploring Big Data Solutions: When To Use Hadoop vs In-Memory vs MPP
| [Hadoop大数据平台架构与实践 | hadoop概述与安装 ](https://www.jianshu.com/p/0e8642e47fd2) |
大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
本篇文章由pekingzcc采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可,转载请注明。
END